Author: Darren Freestone 
Date: 2017-03-01
On 23 February 2017, the first SHA1 collision was announced.
There has been much discussion across many industries as to the impact of this discovery. In digital forensics specifically, the big questions include:
- Can a SHA1 hash still be used for forensic image verification?
- Can a SHA1 hash still be used for hash-set comparisons eg. NSRL ?
- If the answer is ‘yes’ to the above, can an expert witness successfully explain the implications of the collision on the evidence they are presenting, if any?
Not a lot of information has been released so far regarding the exact nature of the weakness. More information will be realised in May 2017. The information we have to go on far can be found in the above article and the site below:
Link: https://shattered.io
Specifically the paper located below:
The three questions above cannot be answered until we can understand exactly what has been achieved and how. The most notable information in the paper is in Table 1 which contains the colliding message blocks which have been discovered and in Table 2 which contains the “prefix” used.
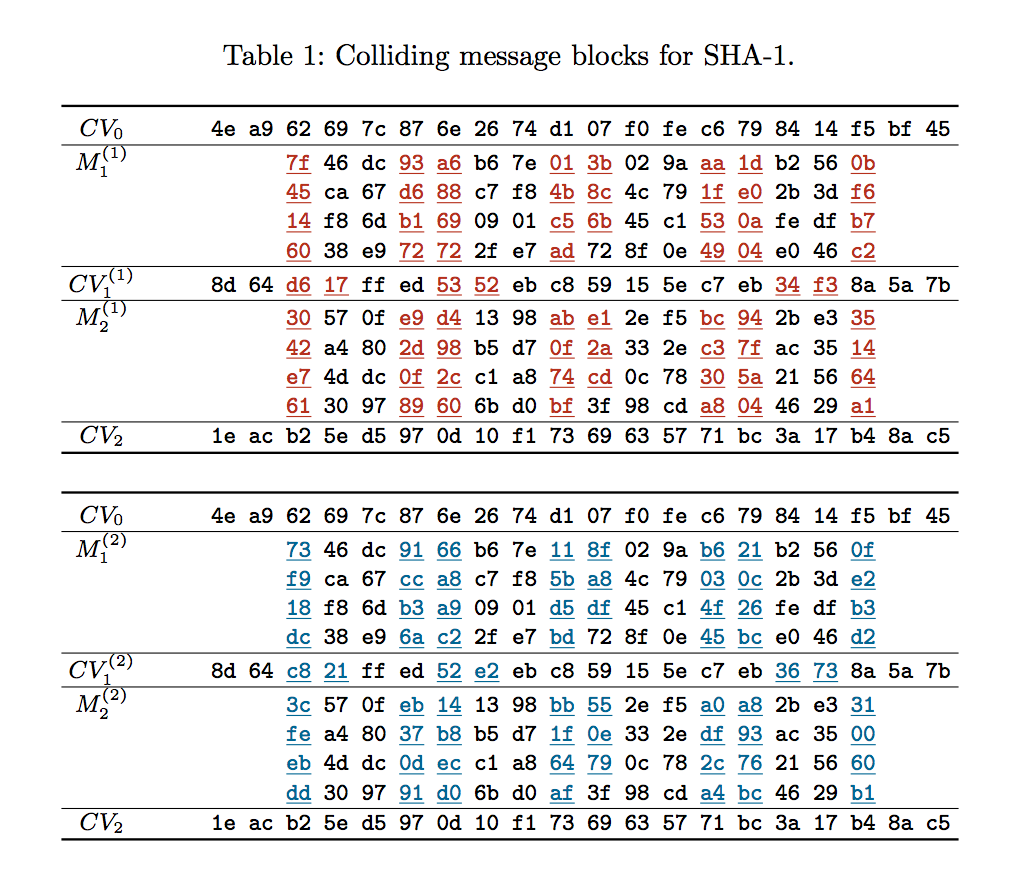
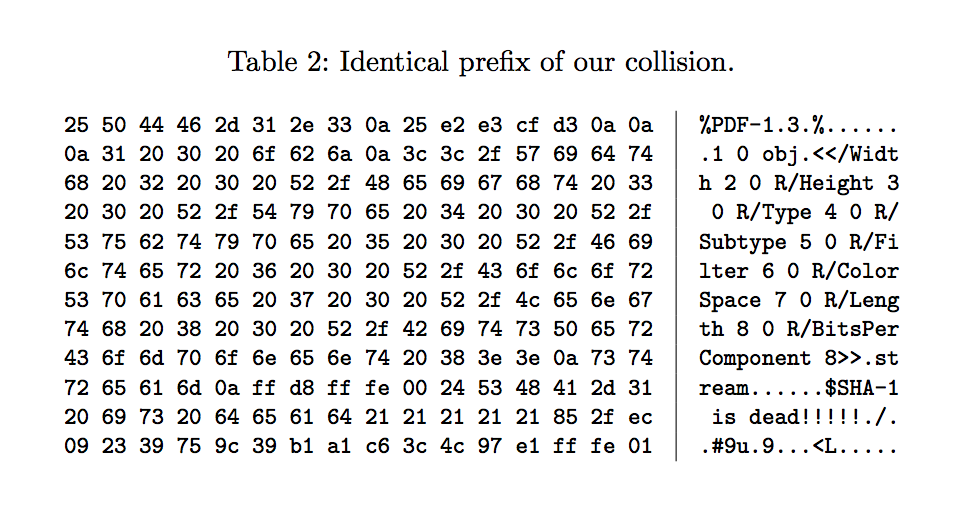
Let’s walk through these table and explain what they mean, in layman’s terms.
Looking firstly at Table 2, we have 192 (0xC0) bytes referred to as a “prefix”. The researchers presumably knew that once a collision was found they would want to use a PDF with an embedded JPEG to encapsulate the differing bytes. These bytes represent a PDF file’s header starting at offset 0 (0x00) with the familiar header of “%PDF-1.3…” followed by the start of an embedded JPEG, found at offset 149 (0x95) with the also familiar header of 0xFF 0xD8 0xFF 0xE0. Something that isn’t typically common to a JPEG file is a comment in the header, but this JPEG has the comment as follows “SHA-1 is dead!!!!!?/?.#9u?9???<L??”. It is likely the comment has been added to pad out the JPEG file and indeed the PDF file to the length of 192 (0xC0) bytes for reasons discussed below.
Next, looking at Table 1, we have the specifics of the collision which has been discovered. Starting with the first line, identified by CV0 we have a value of “4e a9 62 69 7c 87 6e 26 74 d1 07 f0 fe c6 79 84 14 f5 bf 45”. In layman’s terms, a SHA1 has an internal 20 byte (160 bit) “number” at all times which is altered every time a new byte (or bit) of data is passed into it. SHA1 starts off with an initial number value of “67 45 23 01 ef cd ab 89 98 ba dc fe 10 32 54 76 c3 d2 e1 f0”. After the 192 (0xC0) bytes of the “prefix” (Table 2) have been passed into the SHA1 algorithm it’s internal number is equal to “4e a9 62 69 7c 87 6e 26 74 d1 07 f0 fe c6 79 84 14 f5 bf 45”.
So far so good. Next section moving down, M1(1), shows a block of 64 (0x40) bytes. After these bytes have been passed in the internal number has changed to “8d 64 d6 17 ff ed 53 52 eb c8 59 15 5e c7 eb 34 f3 8a 5a 7b”. Next, M2(1), another block of 64 (0x40) bytes is passed in and the internal number changes to “1e ac b2 5e d5 97 0d 10 f1 73 69 63 57 71 bc 3a 17 b4 8a c5”. This is the end of the first half of the Table 1 diagram.
In the second half of the diagram the same steps are happening. The starting value is the same as it was in the previous example “4e a9 62 69 7c 87 6e 26 74 d1 07 f0 fe c6 79 84 14 f5 bf 45” (which represents the “prefix” bytes having been added to the SHA1) and this time two partially different M blocks are being passed in. M1(2) and M2(2) differ from M1(1) and M2(1) as indicated by the red and blue coloured bytes. The black bytes are unchanged. After the M1(2) block is passed in the internal number value changes to one similar but different to before but after the M2(2) is passed in the internal number value changes to match precisely the value from the corresponding step in the previous example, as denoted by CV2.
What does this all mean?
It means that the researchers have taken a “prefix” (Table 2 – the PDF header with embedded JPEG) which they wanted to work with, 192 (0xC0) bytes long, and used it in their calculations to discover two differing groups of bytes, 128 (0x80) bytes in length (2 x 64 bytes) which when appended to the common “prefix” will result in the same internal number value in the SHA1 hash algorithm.
[set 1 of 128 bytes]
[Prefix] + or + [Suffix] = [SHA1 Value]
[set 2 of 128 bytes]
– The prefix is fixed to arrive at a known internal number value inside the SHA1 hash
– The suffix can be anything at all, long or short, any values, no restrictions
Whilst the researches could have started with something far less useful than a PDF with embedded JPEG file, they didn’t, because now this collision can be used to do something really cool. Due to their good understanding of both the PDF and JPEG file formats they were able to ensure that the first differing byte in Table 1 occurs inside the JPEG at the exact location which governs the background colour of the top half of the image. The two byte values I’m referring to are 0x7F and 0x73, respectively. At that precise location in that embedded JPEG, the value of 0x7F gives the image a red background whereas a value of 0x73 gives the image a blue background. All remaining bytes, 61 in total across both blocks, which differ, serve to “correct” the change made in the first byte so that the algorithm will still provide the same hash value. Due to where these bytes are placed in the header of the JPEG, it does not result in corruption or other visible defects in the image. Again, this is due to a very good understanding of the JPEG file format and how to position data within and manipulate offsets within.
Another point worth noting is the comment of “SHA-1 is dead!!!!!?/?.#9u?9???<L??”. Clearly they wanted to let us know that SHA-1 is dead. The characters that follow the exclamation points however appear random and were likely generated to contribute to a “prefix” block which would result in a collision. Or put another way, a comment of “SHA-1 is dead!!!!! ” likely did not result in a successful collision.
For what it’s worth, all changes that occur between the two PDF files, occur within the first few hundred bytes of the embedded JPEG file. The PDF files with the embedded JPEG files removed, are identical. The two PDF files generate the same SHA1 hash. The two JPEG files (when extracted out of the PDFs) do not generate the same SHA1 hash. Copies of the PDF files and JPEG files are attached for reference. The JPEG files are 1024×740 pixels in size. There is no other visible content in the PDF files other than the embedded JPEG file.
Revisiting the questions raised above.
- Can SHA1 still be used for forensic image verification?
In my opinion, yes it can, with some caveats. And I reserve the right to change my opinion when more information is released in May. In digital forensics, we use a SHA1 hash and also an MD5 hash to validate that a bitstream captured on day 0 matches when validated on day 500 after being copied, backed up, restored and/or presented as evidence in court. It protects against accidental corruption. Can it protect against the malicious corruption of a forensic image? Probably, but that’s another question. - Can a SHA1 hash still be used for hash-set comparisons eg. NSRL ?
In my opinion, yes it can, again with some caveats. In digital forensics we use a SHA1 hash and also an MD5 hash to create hash-sets or hash-databases with the values of known good or known bad files, primarily image files but also executables and other files. However, in digital forensics we are generally not depending on these hash values 100%. We use them to narrow down the workload and sort the known from the unknown. We would never run to court with a hash value alone, without first having a look at the file itself, whether that be an image or an executable or something else. - Can an expert witness successfully explain the implications of the collision on the evidence they are presenting, if any?
That depends entirely on the expert and their knowledge level. Now that the SHA1 collision is in the news it will be seen as an easy way to cast some doubt on pending legal proceedings. After reading the paper produced from this research and conducting my own testing I am confident I can explain the collision and it’s implications as an expert witness. But many will not do their own testing, they simply don’t have the time, and they should be careful not to state anything they cannot backup with fact and/or testing.
With those questions answered, new questions are now raised, which could easily be asked of an expert witness:
- Is it possible to alter an existing forensic image with known SHA1 hash value in such a way it will still return the same SHA1 value?
Anything is possible, but based on this research, no. Control over both copies would be required and in this scenario one copy is already fixed with a known SHA1. - Is it possible to create/generate two differing forensic images with matching SHA1 hash values?
Similar question but importantly different. It would in my opinion, be possible, yes. Using the technique in this research. The prefix block would be the start of the MBR of a disk image. It would be used (along with the required CPU/GPU power) to calculate a collision and the two differing blocks which could then be used to obtain a matching hash. Those blocks could be laid down immediately following the prefix and falling within the largely unused “boot code” area of the MBR. The rest of the disk image could follow and function as normal. Why is this important? Because if asked on the witness stand if two seemingly identical yet different forensic images could have the same SHA1 hash value, the answer is almost certainly yes. I feel many of my colleagues might be quick to say no. The opposing council could then produce a copy of two distinct forensic images with matching SHA1 values and ruin your day. - For questions 1 and 2 above, replace “forensic image” with “executable file” and the same answers apply. It would be near impossible based on this research to alter a known whitelisted (SHA1) executable to become malicious and have the hash value match. It would be possible to create two new executables, #1 being benign and #2 being malicious with the same hash values and then obtain a SHA1 whitelisting for #1 and have #2 slide through undetected. The differences between #1 and #2 would have to be very minor, the executable would have to be constructed in such a way to allow malicious code to run with the flip of a bit or two and constructed so that the “correction” bytes don’t result in corruption of the file itself. There could be other reasons I cannot foresee why this isn’t possible (perhaps why the researches chose a PDF instead of an executable) but technically it should be possible.
Conclusion
This research is clearly amazing work by those involved. If anything, it shows just how secure SHA1 has been and is today by how difficult it has been to generate a practical collision. Will SHA1 now be depreciated across the security industry? Absolutely. Is that justified? Absolutely. Does SHA1 need to be depreciated from the digital forensics industry for forensic image verification and for hash-set creation/matching? No. Does it make sense to transition to alternative more secure hash algorithms in digital forensics? Of course. But not overnight in a knee-jerk reaction. Rather, in due course when the opportunity presents.
My advice to digital forensic examiners is to read the research, read the opinions of your peers and do some testing for yourself before forming a strong opinion on the implications of this research. Personally, I sit somewhere in the middle between “The sky is falling” and “Hold my drink, I’ve got this”.
 shattered-1.pdf (412.5 KiB)
shattered-1.pdf (412.5 KiB)
shattered-2.pdf (412.5 KiB)
 shattered-1.jpg (411.5 KiB)
shattered-1.jpg (411.5 KiB)
{kind=link}
 shattered-2.jpg (411.5 KiB)
shattered-2.jpg (411.5 KiB)
{kind=link}